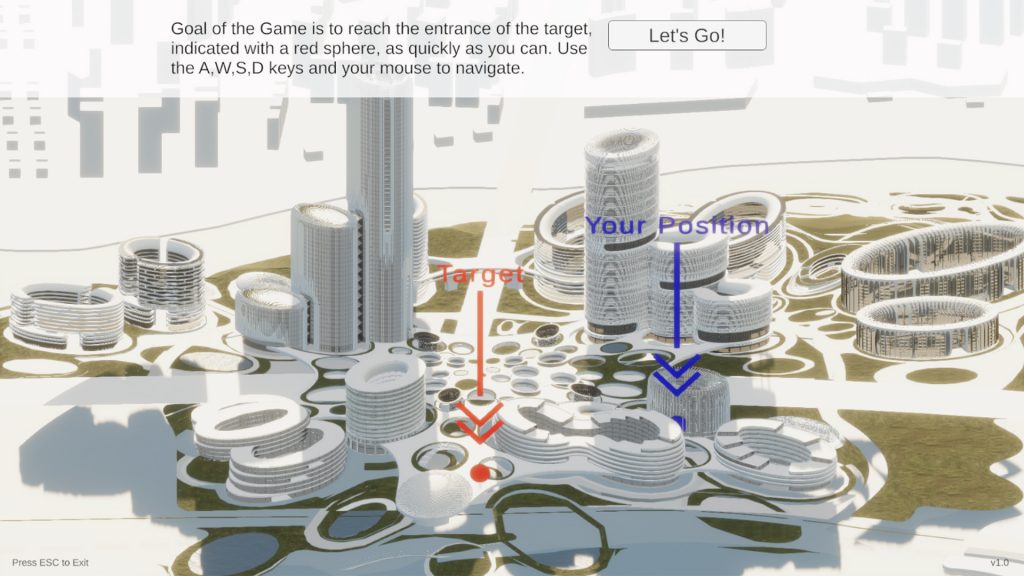
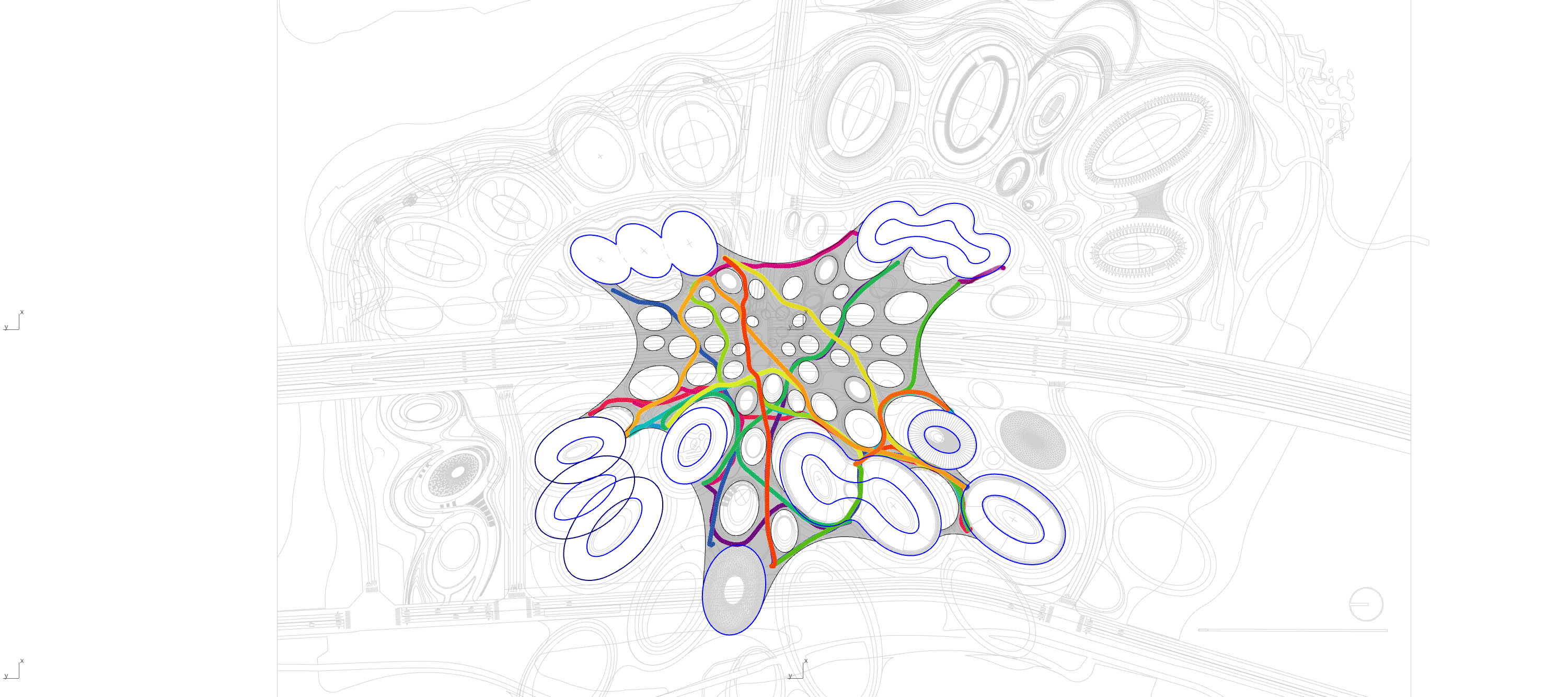
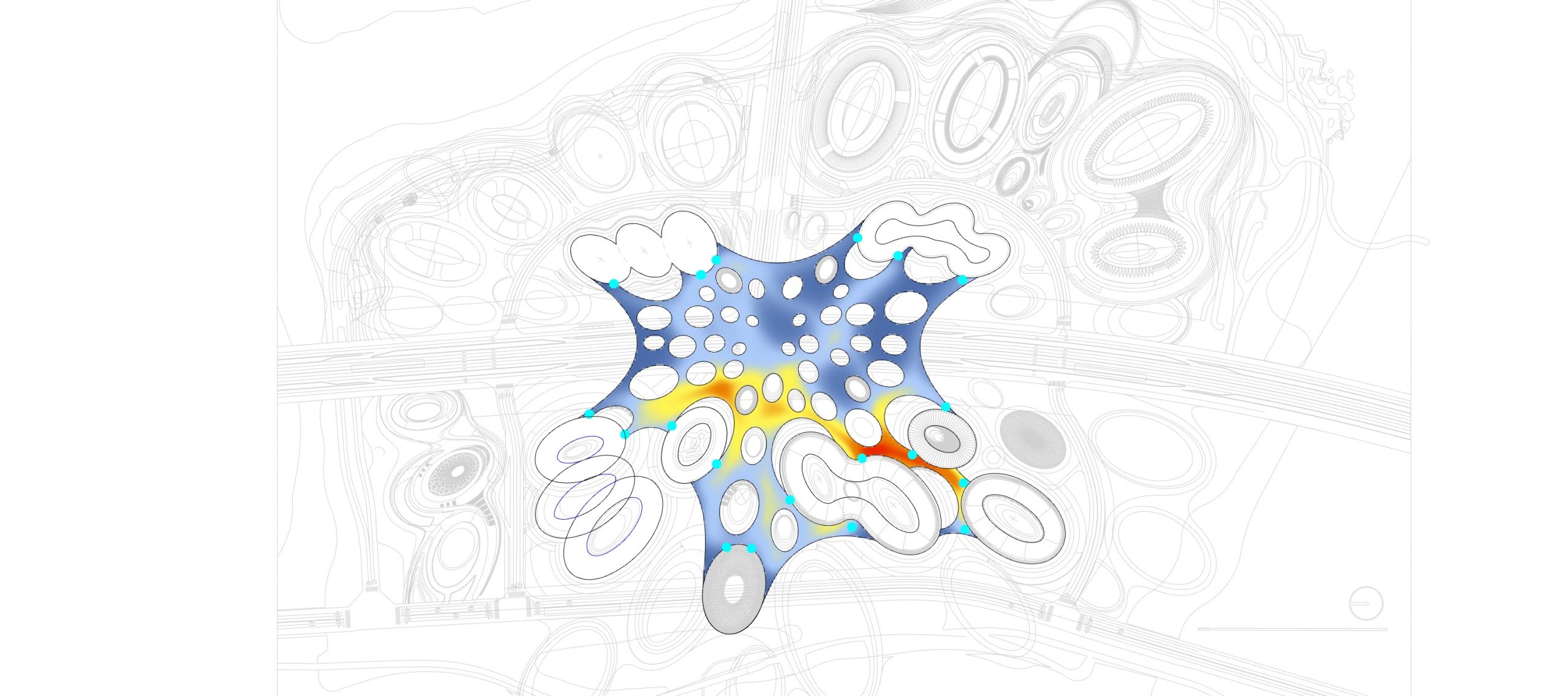
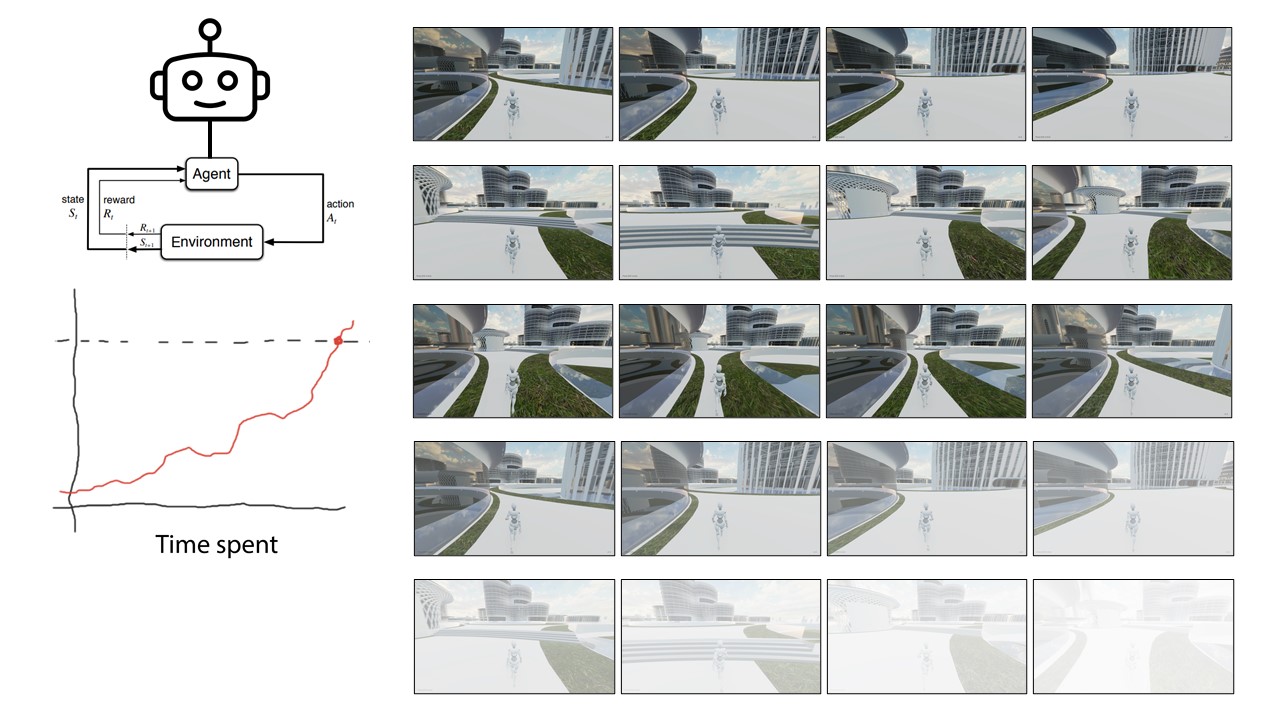
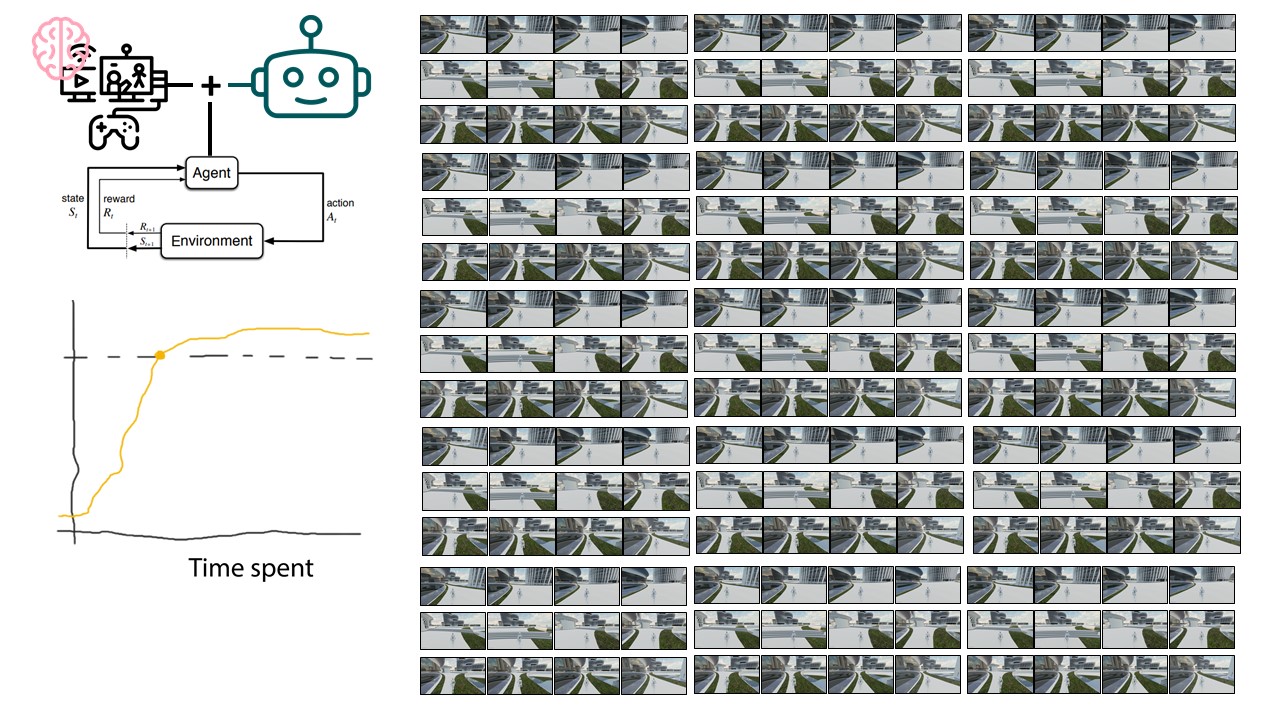
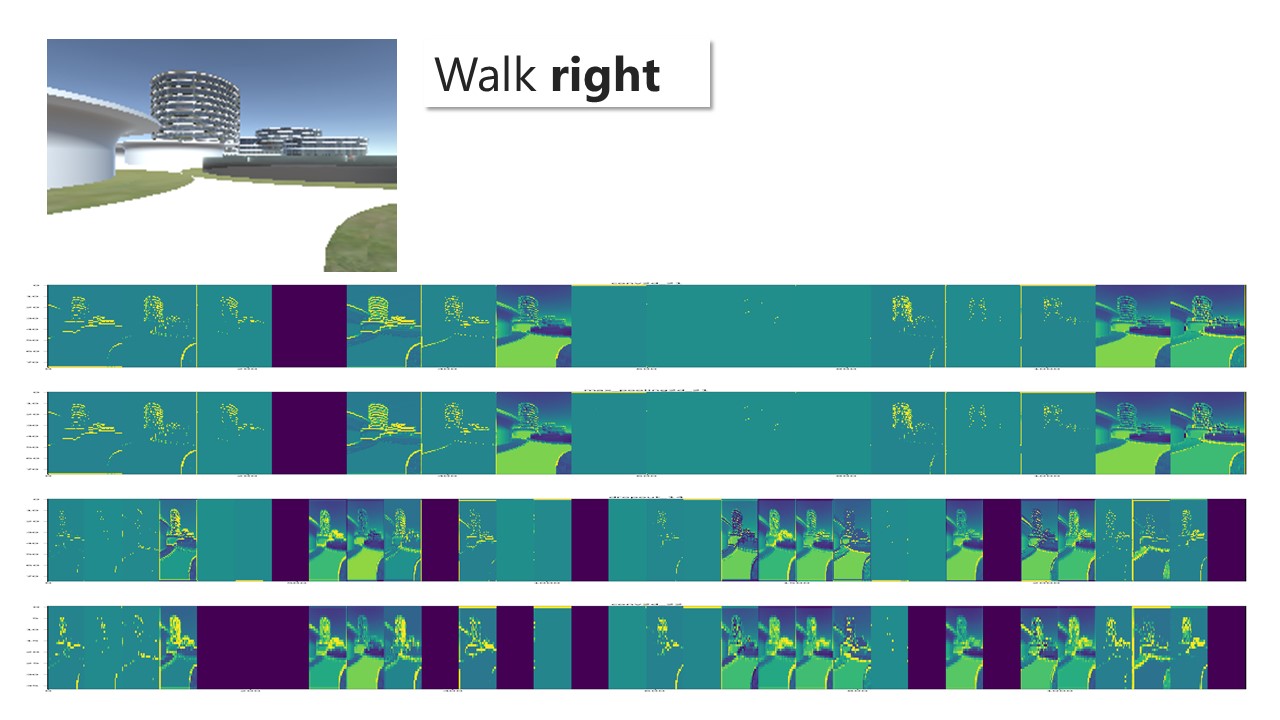
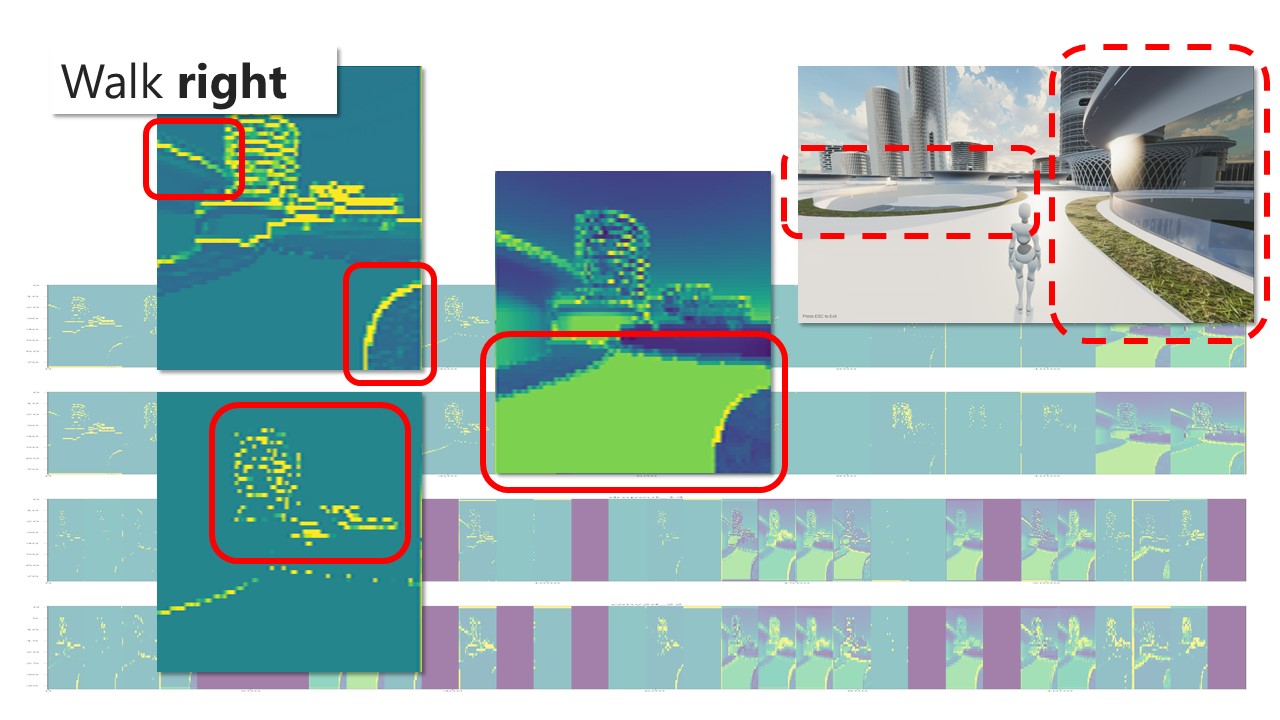
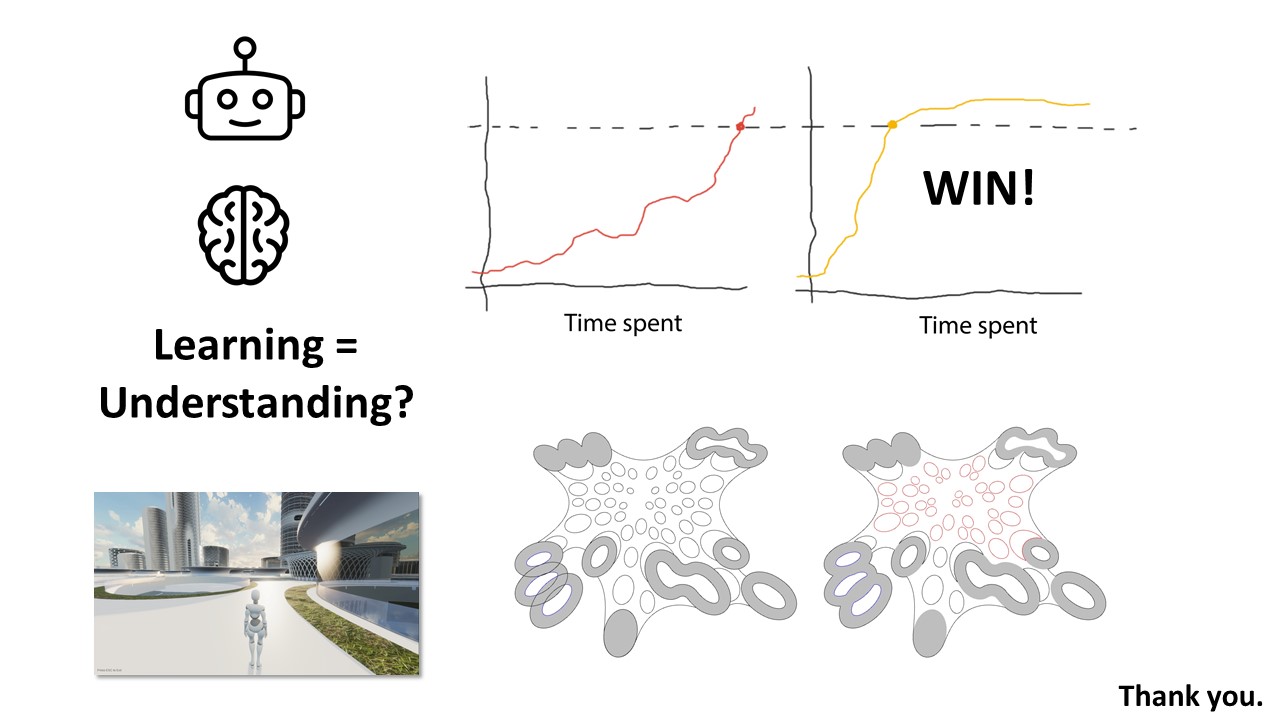
Path finding, footfall analysis and natural path analysis have been important analysis methods for urban designers. Navigability, visual connection between high-frequency pedestrian paths and points of interests, such as shops, amusement, restaurants, but also open plazas and enclosed alleys are important factors for a working urban fabric. Simulating pedestrians has been utilised, especially in the field of civil engineering, egress strategies in stadiums but also path analysis on airports to identify potential dangerous bottlenecks. The SpaceSyntax group at the UCL has provided Architects with their agent simulation tool called DepthmapX. The agents in DepthmapX cast rays in a bespoke field of view and navigate towards the longest ray, which seems quite far from how a human being would navigate space. This project looks into collecting human navigation data through a first-person game and maps the movement taken at each frame. This allows identifying image patterns, such as edges, texture, colour etc., that trigger specific actions of the player in the game to finish a bespoke navigation task. Furthermore, the data can be used as a baseline for a reinforcement learning agent. The trained agent can be used to evaluate the navigability of architectural schemes. The speed at which the agent is learning can be used as a proxy for navigability and therefore feedback to the designer. Good visual cues help the agent and human to navigate space better.

Unicorn Island Masterplan, Zaha Hadid Architects